GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API as well as gives clients the power to ask for exactly what they need and nothing more.
It makes it easier to evolve APIs over time and enables powerful developer tools. At least that’s what we all know it to be. In this post, we’ll look at all the wonderful things about GraphQL and also look at the unpopular “not so good” things about it. Let’s kick it off with the good parts 🙂
The Good
Exact data fetching
The importance and usefulness of GrphQL exact data fetching feature cannot be overemphasized. With GraphQL, you can send a query to your API and get exactly what you need, nothing more and nothing less. It’s really that simple. If you compare this feature with the conventional intuitive nature of REST, you’ll understand that this is a major improvement to the way we initially do things.
GraphQL minimizes the amount of data which is transferred across the wire by being selective about the data depending on the client application’s needs. Thus, a mobile client can fetch less information, because it may not be needed on a small screen compared to the larger screen for the web application.
So instead of multiple endpoints that return fixed data structures, a GraphQL server only exposes a single endpoint and responds with precisely the data a client requested.
Consider a situation where you want to call an API endpoint that has two resources, artists and their tracks.
To be able to request for a particular artist or their music tracks, you will have an API structure like this:
METHOD /api/:resource:/:id:With the traditional REST pattern, if we want to look up a list of every artist using the provided API, we would have to make a GET request to the root resource endpoint like this:
GET /api/artistsWhat if we want to query for an individual artist from the list of artists? then we will have to append the resource ID to the endpoint like this:
GET /api/artists/1In essence, we have to call two different endpoints to get the required data. With GraphQL, every request can be performed on one endpoint, with the actions being taken and data being returned all defined within the query itself. Let’s say we want to get an artisits track and duration, with GraphQL, we’ll have a query like this:
GET /api?query={ artists(id:"1") { track, duration } }This query instructs the API to look up an artist with the ID of 1 and then return its track and duration which is exactly what we wanted, no more, no less. This same endpoint can also be used to perform actions within the API as well.
One request, many resources
Another useful feature of GraphQL is that it makes it simple to fetch all required data with one single request. The structure of GraphQL servers makes it possible to declaratively fetch data as it only exposes a single endpoint.
Consider a situation where a user wants to request for the details of a particular artist, say (name, id, tracks etc). With the traditional REST intuitive pattern, this will require at least two requests to two endpoints /artists and /tracks. However, with GraphQL, we can define all the data we need in the query as shown below:
// the query request
artists(id: "1") {
id
name
avatarUrl
tracks(limit: 2) {
name
urlSlug
}
}Here, we have defined a single GraphQL query to request for multiple resources (artists and tracks). This query will return all and only the requested resources like so:
// the query result
{
"data": {
"artists": {
"id": "1",
"name": "Michael Jackson",
"avatarUrl": "https://artistsdb.com/artist/1",
"tracks": [
{
"name": "Heal the world",
"urlSlug": "heal-the-world"
},
{
"name": "Thriller",
"urlSlug": "thriller"
}
]
}
}
}As can be seen from the response data above, we have fetched the resources for both /artists and /tracks with a single API call. This is a powerful feature that GraphQL offers. As you can already imagine, the applications of this feature for highly declarative API structures are limitless.
Modern compatibility
Modern applications are now built in comprehensive ways where a single backend application supplies the data that is needed to run multiple clients. Web applications, mobile apps, smart screens, watches etc can now depend only on a single backend application for data to function efficiently.
GraphQL embraces these new trends as it can be used to connect the backend application and fulfill each client’s requirements ( nested relationships of data, fetching only the required data, network usage requirements, etc.) without dedicating a separate API for each client.
Most times, to do this, the backend would be broken down into multiple microservices with distinct functionalities. This way, it becomes easy to dedicate specific functionalities to the microservices through what we call schema stitching. Schema stitching makes it possible to create a single general schema from different schemas. As a result, each microservice can define its own GraphQL schema.
Afterward, you could use schema stitching to weave all individual schemas into one general schema which can then be accessed by each of the client applications. In the end, each microservice can have its own GraphQL endpoint whereas one GraphQL API gateway consolidates all schemas into one global schema to make it available to the client applications.
To demonstrate schema stitching, let’s consider the same situation employed by Sakho Stubailo while explaining stitching where we have two related APIs’s. The new public Universes GraphQL API for Ticketmaster’s Universe event management system and the Dark Sky weather API on Launchpad, created by Matt Dionis. Let’s look at two queries we can run against these APIs separately. First, with the Universe API, we can get the details about a specific event ID:
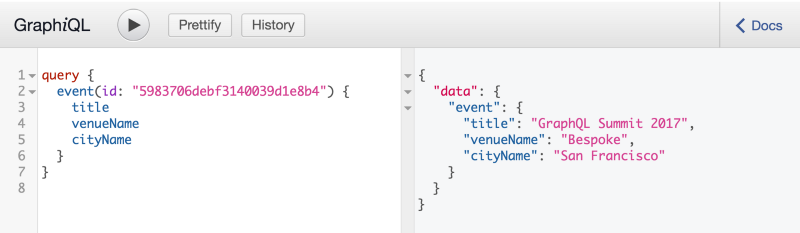
With the Dark sky weather API, we can get the details of the same location like so:

Now with GraphQL schema stitching, we could do an operation to merge the two schemas in such a way that we could easily send those two queries side by side:

Wonderful isn’t it. You can take an in-depth look at GraphQL schema stitching by Sashko Stubailo to get a deeper understanding of the concepts involved.
This way, GraphQL makes it possible to merge different schemas into one general schema where all the clients can get resources from hence, embracing the new modern style of development with ease.
Field level deprecation
This is one GraphQL feature that personally gives me joy. As developers, we are used to calling different versions of an API and often times getting really weird responses. Traditionally, we version API’s when we’ve made changes to the resources or to the structure of the resources we currently have hence, the need to deprecate and evolve a new version.
For example we can have an API like api.domain.com/resources/v1 and at some point in the later months or years, a few changes would have happened and resources or the structure of the resources will have changed, hence, the next best thing to do will be to evolve this API to api.domain.com/resources/v2 to capture all the recent changes.
At this point, some resources in v1 will have been deprecated (or left active for a while until users have migrated to the new version) and on receiving a request for those resources, will get unexpected responses like deprecation notices.
In GraphQL, it is possible to deprecate API’s on a field level. When a particular field is to be deprecated, a client receives a deprecation warning when querying the field. After a while, the deprecated field may be removed from the schema when not many clients are using it anymore.
As a result, instead of completely versioning the API, it is possible to gradually evolve the API over time without having to restructure the entire API schema.
The bad
Caching
Caching is the storage of data so that future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation or the duplicate of data stored elsewhere. The goal of caching an API response is primarily to obtain the response from future requests faster. Unlike GraphQL, caching is built into in the HTTP specification which RESTful APIs are able to leverage.
With REST you access resources with URLs, and thus you would be able to cache on a resource level because you have the resource URL as identifier. In GraphQL, this becomes complex as each query can be different even though it operates on the same entity.
In one query you might be interested in just the name of an artist, however, in the next query you might want to get the artists’ tracks and release dates. This is the point where caching is mostly complex as it’ll require field level caching which isn’t an easy thing to achieve with GraphQL since it uses a single endpoint.
That said, the GraphQL community recognizes this difficulty and has since been making efforts to make caching easier for GraphQL users. Libraries like Prisma and Dataloader (built on GraphQL) have been developed to help with similar scenarios. However, it still doesn’t completely cover things like browser and mobile caching.
Query performance
GraphQL gives clients the power to execute queries to get exactly what they need. This is an amazing feature however, it could be a bit controversial as it could also mean that users can ask for as many fields in as many resources as they want.
For instance, a user defines a query that asks for a list of all the users that commented on all the tracks of a particular artist. This will require a query like this:
artist(id: '1') {
id
name
tracks {
id
title
comments {
text
date
user {
id
name
}
}
}
}This query could potentially get tens of thousands of data in response.
Therefore, as much as it is a good thing to allow users to request for whatever they need, at certain levels of complexity, requests like this can slow down performs and immensely affect the efficiency of GraphQL applications.
For complex queries, a REST API might be easier to design because you can have several endpoints for specific needs, and for each endpoint, you can define specific queries to retrieve the data in an efficient way. This might also be a bit controversial given that the fact that several network calls can as well take a lot of time, but if you are not careful, a few big queries can bring your server down to its knees.
Data mismatch
As we exemplified before while building with GraphQL on the backend, often than not, your database and GraphQL API will have similar but different schemas, which translate to different document structures. As a result, a track from the database will have a trackId property while the same track fetched through your API will instead have a track property on the client. This makes for client/server-side data mismatch.
Consider getting the name of the artist of a particular track on the client-side, it’ll look like this:
const getArtistNameInClient = track => {
return artist.user.name
}However, doing the exact same thing on the server-side will result in an entirely different code like this:
const getArtistNameInServer = track => {
const trackArtist = Users.findOne(track.userId)
return trackArtist.name
}By extention, this means that you’re missing out on GraphQL’s great approach to data querying on the server.
Thankfully, this is not without a fix, It turns out that you can run server-to-server GraphQL queries just fine. How? you can do this by passing your GraphQL executable schema to the GraphQL function, along with your GraphQL query:
const result = await graphql(executableSchema, query, {}, context, variables);According to Sesha Greif, it is important to not just see GraphQL as just a pure client-server protocol. GraphQL can be used to query data in any situation, including client-to-client with Apollo Link State or even during a static build process with Gatsby.
Schema similarities
When building with GraphQL on the backend, you can’t seem to be able to avoid duplication and code repetition especially when it comes to schemas. First, you need a schema for your database and another for your GraphQL endpoint, this involves similar-but-not-quite-identical code, especially when it comes to schemas.
It is hard enough that you have to write very similar code for your schemas regularly, but it’s even more frustrating that you also have to continually keep them in sync.
Conclusion
GraphQL is an exciting new technology, but it is important to understand the tradeoffs before making expensive and important architectural decisions. Some APIs such as those with very few entities and relationships across entities like analytics APIs may not be very suited for GraphQL. However, applications with many different domain objects like e–commerce applications where you have items, users, orders, payments, and so on may be able to leverage GraphQL much more.
GraphQL is a powerful tool, and there are many reasons to choose it in your projects but do well not to forget that the most important and often times the best choice, is choosing whichever tool is right for the project in consideration. The good and bad points I have presented here may not always apply, but it is worth taking them into consideration while looking at GraphQL to see if they can help your project or to know if the cons have been addressed.
Source: Scotch.io